No man ever steps into the same river twice

Heraclitus believed that you can never step into the same river twice because everything is constantly changing. He thought this concept was crucial to how the universe operates. In simpler terms, his analogy suggests that even though a river may look the same, the water and life within it are always in change.
This analogy can also be applied to streams in software development, particularly in integration. Although you have the same streaming object instance in hand, the data within is constantly changing. Just as we must handle the analogy’s life with care, we also need to treat the data in streams with great caution.
In one of our projects, my team was responsible for handling and migrating 1.6 terabytes of sales, invoice, and customer data from one cloud provider to another. Considering the amount of data, possible tools would be “kafka connect”, “apache airflow”, “talend”, “apache camel”, “apache nifi”, “eclipse vert.x”, “spark streaming” and even “custom code piece with streaming capabilities”. Some commercial tools which has more ETL/ELT capabilities can also be considered here. there are some cloud solutions as well obviously. But since the data is protected by firewall and my team is only allowed to access the source using mulesoft instances they focused on mule as the tool.
1.6 TB of data can not be handled without streaming if you are not using a file system backed tool. Like apache airflow can handle this data with temp file export/import in the migration flow that do not necessary to stream all the time. With spark streaming, you can tune the cluster in some extend to handle 1.6TB data in one shot, but not using streaming altough product name itself contain streaming.
Mulesoft has a capability called batch processing which can handle batch of list/set/array of data objects parallely/serially that can be used with streaming. this is a great future that you need to handle reasonable amount of data and the data parts/instances which every of the array is an event lets say.
When the batch processing was used, my team run into an error stated as “No Space Left On Device”. its weird to get this exception at first since we thought that we were using streaming of java objects and we have no file system dependency. it was quite difficult to get to know that, GC is purging this data on file system. My expert consultant Ahmet found out this info article.
Solution was, after using batch processing, trigger a full GC explicitly. “java!java::lang::Runtime::getRuntime().gc()”. This particular problem was solved and team contined to migrate the data.
But, then, I started thinking, why, why on earth, file system is causing issue altough it should not be in the picture. After some digging, found out that batch processing is using ehcache (old school folks might know) behind the scene and objects are piled up to be processed as cache objects which backed by file system. And file system is being purged only after the processed cache instances deleted by the GC. I have not checked but most probably finalized() method that being called during destroying java instances in memory invalidates the cache objects and purge the file system.
Moreover, the challenging aspect was that the team attempted to increase worker size vertically, resulting in reduced garbage collection, and consequently, fewer file system purges, leading to more instances of “No Space Left On Device.” error. its something not expected as logical thinking.
Therefore, I instructed my team not to utilize batch processing for this scenario. As my decisions serve as the standard for all platform/product choices, I prefer solutions that do not involve intricate elements requiring specific handling in unique situations.
From a platform architecture and engineering perspective, an ideal solution is one that can be universally applied without the need for special tunings or adjustments for exceptional cases. A robust and scalable architecture should be designed to handle a wide range of scenarios and data volumes without relying on bespoke configurations or optimizations for specific instances. This approach promotes consistency, ease of maintenance, and a streamlined implementation process across the entire platform. It ensures that the solution is resilient, performs well under various conditions, and can be efficiently managed without the burden of excessive customization for unique circumstances.
A more general and hassle-free version solution for this case is streaming the source and iterating over this stream.
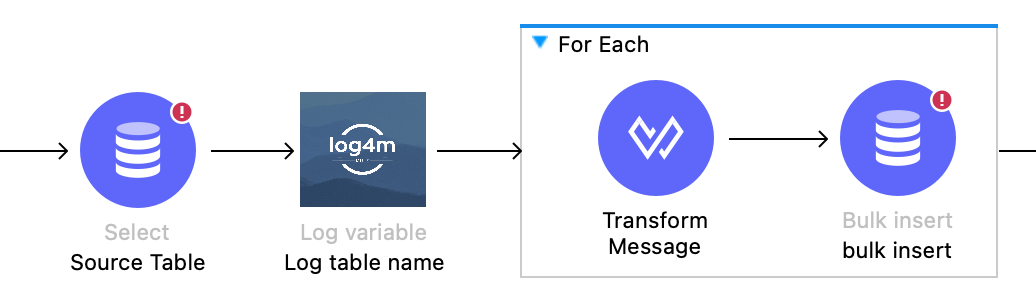
As can easyly be understood, the idea is, stream the data from source and after every iteration write to destination in batches. the batchses on the write hand side is important as write data as bulk is way faster than one-by-one.
Here, we encounter another significant issue; there is a crucial need for a limit on the bulk insert size array. Without it, we are bound to encounter an out-of-memory exception.
Also at this point you might ask, why to not stream this data to destination like its coming, due two reasons,
- some destinations, like teradata, have some insert limit on one transaction, so we need to control the numbers of DML in every transaction
- transform activity in mulesoft is not stream capable. :(
You might wonder how to stream this when the transform breaks the stream in the middle. The solution lies in using java.util.iterator. Mulesoft converts the source data into an iterator. Then, in each iteration of the for-loop, iterator.next() retrieves the data, and a new list object is created for every for-loop-batch-size. This particular list is subsequently used for bulk insertion into the destination.
There is an obvious limit for bulk insertion, before getting an OOM exception.
As we are dealing with a substantial amount of data, it is essential to work on an estimation to determine the time required for the data migration. Out of the 5 billion records, we selected 100,000 records and gathered the following metrics.
| iteration-1 | iteration-2 | iteration-3 | iteration-4 | iteration-5 | ||||
|---|---|---|---|---|---|---|---|---|
| fetch | for | duration | duration | duration | duration | duration | start | end |
| 50 | 50 | 00:13:11 | 00:13:00 | 00:13:03 | 00:12:56 | 00:13:35 | 11:14:37.285 | 11:28:12.197 |
| 100 | 50 | 00:12:33 | 00:12:39 | 00:12:45 | 00:12:33 | 00:12:52 | 13:48:37.372 | 14:01:29.618 |
| 1000 | 50 | 00:12:04 | 00:12:14 | 00:11:59 | 00:12:10 | 00:12:36 | 13:36:00.504 | 13:48:36.211 |
| 2000 | 50 | 00:12:00 | 00:12:10 | 00:12:21 | 00:12:13 | 00:12:29 | 13:23:30.923 | 13:35:59.500 |
| 5000 | 50 | 00:12:07 | 00:12:09 | 00:12:22 | 00:12:18 | 00:12:37 | 13:10:52.097 | 13:23:29.564 |
| 10000 | 50 | 00:12:08 | 00:12:16 | 00:12:28 | 00:12:12 | 00:12:42 | 12:58:08.681 | 13:10:50.761 |
| 100 | 100 | 00:08:41 | 00:08:53 | 00:09:01 | 00:08:44 | 00:08:59 | 12:49:07.925 | 12:58:06.592 |
| 1000 | 100 | 00:08:07 | 00:08:26 | 00:08:31 | 00:08:15 | 00:08:30 | 12:40:37.510 | 12:49:07.066 |
| 2000 | 100 | 00:08:14 | 00:08:28 | 00:09:05 | 00:08:21 | 00:08:41 | 12:31:55.814 | 12:40:36.625 |
| 5000 | 100 | 00:08:19 | 00:08:25 | 00:08:42 | 00:08:19 | 00:08:38 | 12:23:16.563 | 12:31:54.744 |
| 10000 | 100 | 00:08:29 | 00:08:28 | 00:08:30 | 00:08:09 | 00:08:40 | 12:14:34.678 | 12:23:15.035 |
| 1000 | 500 | 00:04:53 | 00:04:49 | 00:04:39 | 00:04:33 | 00:04:59 | 12:09:33.666 | 12:14:32.534 |
| 2000 | 500 | 00:04:53 | 00:04:50 | 00:04:40 | 00:04:32 | 00:04:58 | 12:04:35.043 | 12:09:32.640 |
| 5000 | 500 | 00:04:52 | 00:04:53 | 00:04:55 | 00:04:36 | 00:05:02 | 11:59:31.898 | 12:04:33.583 |
| 10000 | 500 | 00:04:55 | 00:05:02 | 00:05:19 | 00:04:34 | 00:05:00 | 11:54:30.809 | 11:59:30.451 |
| 1000 | 1000 | 00:04:25 | 00:04:38 | 00:04:55 | 00:04:09 | 00:04:25 | 11:50:03.143 | 11:54:28.179 |
| 2000 | 1000 | 00:04:17 | 00:04:30 | 00:04:47 | 00:04:08 | 00:04:23 | 11:45:38.659 | 11:50:02.134 |
| 5000 | 1000 | 00:04:22 | 00:04:20 | 00:05:05 | 00:04:15 | 00:04:24 | 11:41:14.063 | 11:45:37.573 |
| 10000 | 1000 | 00:04:29 | 00:04:31 | 00:05:00 | 00:04:12 | 00:04:33 | 11:36:39.972 | 11:41:12.524 |
| 20000 | 1000 | 00:04:41 | 00:04:41 | 00:04:41 | 00:04:41 | 00:04:41 | 14:14:33.752 | 14:19:14.946 |
| 2000 | 2000 | 00:04:09 | 00:04:12 | 00:04:40 | 00:03:56 | 00:04:08 | 11:32:29.052 | 11:36:37.527 |
| 5000 | 2000 | 00:04:17 | 00:04:10 | 00:04:43 | 00:04:22 | 00:04:14 | 11:28:13.867 | 11:32:27.775 |
| 10000 | 2000 | 00:04:30 | 00:04:08 | 00:04:44 | 00:04:28 | 00:04:15 | 14:01:31.963 | 14:05:47.009 |
| 5000 | 5000 | 00:05:12 | 00:05:12 | 00:05:12 | 00:04:22 | 00:04:16 | 14:05:48.766 | 14:10:04.904 |
| 10000 | 5000 | 00:05:03 | 00:05:03 | 00:05:03 | 00:04:34 | 00:04:23 | 14:10:07.483 | 14:14:30.431 |
| 20000 | 5000 | 00:04:28 | 00:04:27 | 00:04:27 | 00:04:28 | 00:04:27 | 14:19:18.580 | 14:23:46.067 |
| 20000 | 10000 | 00:04:57 | 00:04:58 | 00:04:56 | 00:04:57 | 00:04:57 | 14:23:49.650 | 14:28:47.010 |
| 20000 | 20000 | 00:00:00 | 00:00:00 | 00:00:00 | 00:00:00 | #VALUE! | 14:28:50.285 | OOM |
As can be seen above table, 20k batches in for-loop is leading the out of memory exception, depending on our data which consist of ~70 column in every row. so we need to choose at the most 5k in every iteration for insertion not to close to the OOM. having small numbers in fetch and insertion as expected increae the duration of operation.
Given the total volume of 5 billion records, and considering that the durations mentioned above are only for 100,000 records, the overall duration will be 50,000 times longer than the instances described earlier.
max and minimum total durations with given metrics (50/50 max and 2000/1000 min)
- max => 13 min, 35 sec x50k = 40750000 sec = 11319.4 hour = 471.6 days
- min => 4 min, 23 sec x50k = 13150000 sec = 3652.7 hour = 152.1 days
as can be seen, choosing the correct number is very important if you needed to stick to this approach.
abviosly this numbers are not acceptable, the solution will use the 2000/1000 fetch and for-loop-batch-insert number and some parallelizm based on entity types. on top of that there will be some chunk of data for one entitiy based on mod, or data, or seq number or some identifier. than this duration will be decreased to some reasonable duration.
lets say we have 5 entity types that can be run parallel, 30 days per entity type for one run, adding 20 parallel per run makes it 1.5 days. too much. we need to digg more alternatives :)
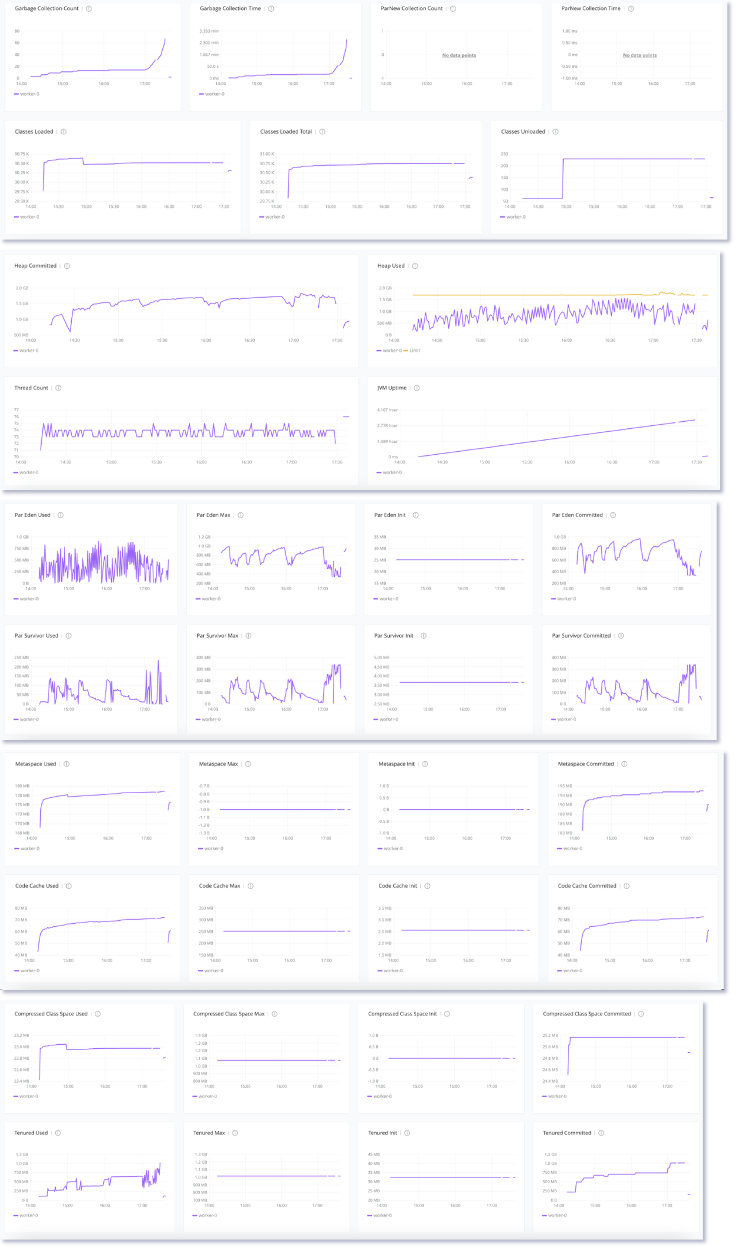
when it comes to jvm profiling, below metrics show that the higher the for-loop batch size the higher tenured/oldgen space usage which leads the OOM. in less batch numbers the eden space usage and eventually full GC count are less and in small duration.